
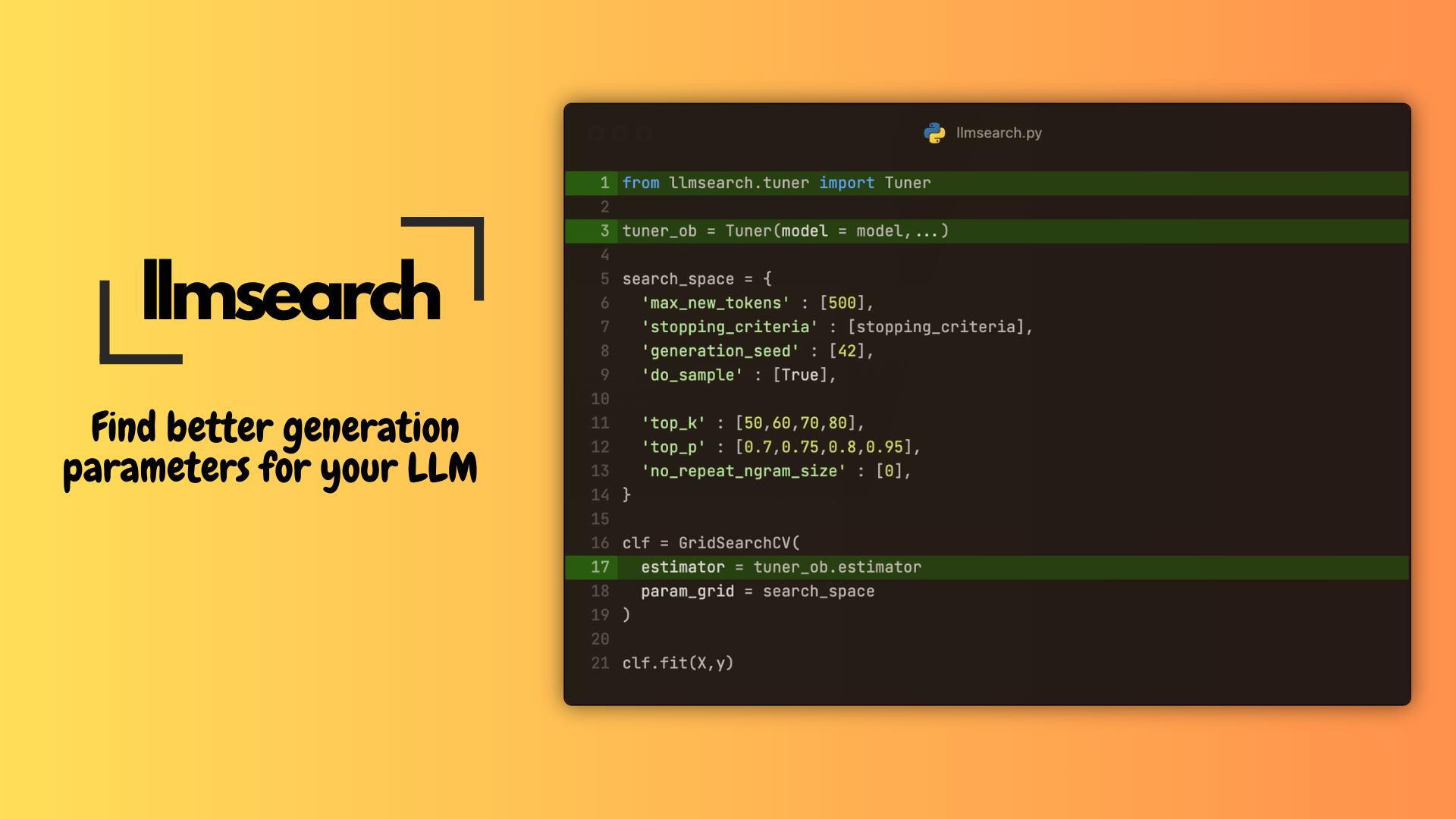
Find better generation parameters for your LLMs using llmsearch
The BackstoryPermalink
Back when GPT-J from EleutherAI had released I remember using it for a question answer extraction task from a span of text using few shot learning(you provide few examples in the prompt before the actual question that you want get answerd). It was a small 6B model and in my initial trials it did not work really great, Then I started playing with the generation parameters of the model. I tried multiple of them manually until I reached a configuration which seemed to do much better that what I originally started with. These are the set of generation parameters that I manually found for the task.
{
"max_new_tokens" : 15,
"min_new_tokens" : 5,
"num_beams" : 3,
"use_cache" : True,
"no_repeat_ngram_size" : 4,
}
I thought to myself, there should be an easier way to do this. Generation Parameters are more than an icing on the cake for a language model particularly small ones, it can make or break your model, in-fact a lot of the latest model releases nowadays include a predefined set of generation params that the authors recommend, here is an example for LLAMA 3 8B that was released on huggingface.
This motivated me to build llmsearch , An easier way of finding generation parameters using the familiar scikit-learn interface.
Repository - ![]()
Documentation - ![]()
Main Arc Step-by-Step Guide to use llmsearchPermalink
Following Example will show an example a LLAMA-3 Model specifically casperhansen/llama-3-8b-instruct-awq on the infamous samsum dataset. We will use a quantized AWQ model.
Notebook ![]() if you want to follow along.
if you want to follow along.
Install dependenciesPermalink
# install llmsearch
!pip install llmsearch[pynvml] -q
# pinning to specific versions to avoid import issues - https://github.com/casper-hansen/AutoAWQ/issues/374
# only required if using awq model
!pip install transformers==4.38.2 -q
!pip install torch@https://download.pytorch.org/whl/cu121/torch-2.2.0%2Bcu121-cp310-cp310-linux_x86_64.whl#sha256=c441021672ebe2e5afbdb34817aa85e6d32130f94df2da9ad4cb78a9d4b81370 -q
!pip install autoawq==0.2.4 autoawq_kernels==0.0.6 -q
# install dependencies required for this example
!pip install accelerate==0.30.1 py7zr==0.21.0 evaluate==0.4.0 rouge_score==0.1.2 -q
Import required librariesPermalink
# Autocompletion
%config Completer.use_jedi = False
# Autoreload
%load_ext autoreload
%autoreload 2
import awq
import torch
import transformers
import llmsearch
import evaluate
import datasets
import numpy as np
from awq import AutoAWQForCausalLM
from sklearn.model_selection import GridSearchCV
from transformers import AutoTokenizer, AutoModelForCausalLM, StoppingCriteriaList
from llmsearch.tuner import Tuner
from llmsearch.scripts.stopping_criteria import MultiTokenStoppingCriteria
Set some variables that we will use later.
seed = 42
batch_size = 2
num_samples = 10
device = "cuda:0"
Load model & datasetPermalink
Load the casperhansen/llama-3-8b-instruct-awq model with the refs/pr/6 revision, This revision has the right EOS token configured as per the official LLAMA 3 repository. Not using the correct token mapping produces incorrect output from the model. We will use the samsum dataset to run generation hyper-parameter search on.
model_id = "casperhansen/llama-3-8b-instruct-awq"
revision = "refs/pr/6"
tokenizer = AutoTokenizer.from_pretrained(model_id,revision = revision)
tokenizer.padding_side = "left"
model = AutoAWQForCausalLM.from_quantized(
model_id, fuse_layers=True, device_map={"": device}, revision = revision
)
dataset = datasets.load_dataset("samsum")['train']
sample_dataset = dataset.shuffle(seed = seed).select(range(num_samples))
# These are required to make the model end the sequence correctly - https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct#transformers-automodelforcausallm
terminators = [
128001,
128009,
]
Define dataset preprocessor and metricPermalink
For a particular dataset, we can define columns in the dataset that will be used for evaluation(eval_cols) and columns that will be used while running inference(input_cols).
Once you have decided on a metric, a evaluation function needs to be defined that takes in two arguments y_true : list & y_pred : list. y_pred is what the model will predict, y_true contains(for each item in the list) the evaluation columns (eval_cols) defined in your Tuner object, more on this later.
Your dataset preprocessor should take in single item from your dataset and return a string which is ready to be tokenized and can be passed directly into the model. In this example we convert an item of the dataset into the chat template format. The dataset preprocessor function should take in a tokenizer and kwargs , the kwargs will contain keys that you have defined as input_cols when you create the Tuner object, more on this in the next section.
# create a function that can be used for evaluation, should take in y_true (list[dict]), y_pred (list) and return a metric
rouge = evaluate.load('rouge')
def get_rouge_score(y_true : list, y_pred : list):
return np.mean(rouge.compute(predictions=y_pred, references=[item['summary'] for item in y_true], use_stemmer=True, use_aggregator=False)['rouge2'])
# Define a dataset preprocessor that is called for every example in the dataset separately - Should take in tokenizer & kwargs and return a string that can be input directly to the model, here we apply chat template which most decoder models use
def sample_to_chat_format(tokenizer, **kwargs):
messages = [
{
'role' : "system",
'content' : "You are a helpful AI assistant."
},
{
'role' : "user",
'content' : f"Summarize the following text in less than 50 words: {kwargs['dialogue']}"
}
]
return tokenizer.apply_chat_template(messages, tokenize = False, add_generation_prompt = True)
Define Tuner objectPermalink
This is the important object and where most of the magic happens, This takes in what you have defined till now and abstracts into a Tuner object. It also preprocesses the dataset so that you are ready to do inference. The column_mapping is what is used to identify what are columns in the dataset that will be used for preprocessing/inference (input_cols) and which one will be used for evaluation (eval_cols). This is how Tuner knows what arguments to send to the sample_preprocessor function (to preprocess the dataset) and which ones to scorer (to evaluate the model).
# define tuner object, this preprocesses the dataset and creates an LLMEstimator that can be run with GridSearchCV / RandomizedSearchCV of scikit-learn
tuner_ob = Tuner(
model=model,
tokenizer=tokenizer,
dataset=sample_dataset,
device="cuda:0",
# the tuner module automatically reduces the batch size while running inference if it goes OOM
batch_size=batch_size,
tokenizer_encode_args={"padding": "longest",'truncation' : True, "add_special_tokens": False, 'max_length' : 1024},
tokenizer_decode_args={"spaces_between_special_tokens": False, 'skip_special_tokens' : True},
# pass in the scorer that we will be used to evaluate (input to this function is a batch)
scorer=get_rouge_score,
# pass in `dataset` preprocessor, this is run on the passed in dataset before feeding into the model, input of this function is a single example
sample_preprocessor=sample_to_chat_format,
seed=seed,
# column mapping used to identify input and evaluation columns (these columns are passed in to the evaluation function (scorer) & the dataset preprocessor(sample_preprocessor))
column_mapping={"input_cols": ["dialogue"], "eval_cols": ["summary"]},
)
You can examine if the dataset was preprocessed correctly, Tuner preprocessed the dataset and stores the input and output at _X & _y respectively.
# Check to see if dataset is processed as expected, `Tune` populates `_X` with the processed input and `_y` with `column_mapping.eval_cols`
print(f"Inputs: ")
for _x, _y in zip(tuner_ob.dataset['_X'][:3], tuner_ob.dataset['_y'][:3]):
print(f"Input: {_x}")
print('\n')
print(f"Output: {_y}")
print('\n\n')
print('---' * 15,'\n\n')
Inputs:
Input: <|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Summarize the following text in less than 50 words: Lucy: omg did you see JK this morning?
Sue: I try to avoid it lol
Lucy: you should have seen it it was disgusting
Sue: I cant do it anymore i try to listen to the radio in the mornings.. jk makes you think the whole world is full of idiots lol
Lucy: you may be right I dont know how some of them can go on there in public for the world to see
Sue: I would die if I got a call to go on there lol
Sue: could you imagine ha ha
Lucy: I would piss myself If I saw you and Andy up there
Sue: over my dead body !<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Output: {'summary': "Sue doesn't watch JK any more as it's disgusting."}
---------------------------------------------
Input: <|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Summarize the following text in less than 50 words: Wendy: What's up?
Simon: Nothing much. I'm painting my cupboards.
Angela: Cool what colour?
Simon: Green.
Ben: I'm just chilling in the garden.
Angela: Nice weekend! I'm about to meet Chris.
Wendy: Say hello from me!
Angela: Will do! And how is your weekend, Wendy?
Wendy: Very lazy... The week was hard at work, I really needed some rest.
Ben: We should all come and visit Simon in his new apartment!
Simon: You are welcome, guys! Whenever you wish.
Ben: I should be in Bournemouth next week.
Simon: I'm not going anywhere :-)
Ben: Cool, I'll call you next week.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Output: {'summary': 'This weekend Wendy is very lazy because she worked hard at work, and Angela is meeting Chris. Simon is chilling in the garden and painting his cupboards green. Next week, Ben, Angela, Chris and Wendy will visit him in his new apartament.'}
---------------------------------------------
Evaluation Before TuningPermalink
Before running a search, you should evaluate what score default settings provide, since the objective is to find a better score that what you have now.
You can get the score by calling tuner_ob.get_score with the default parameters. I have used 3 parameters here. max_new_tokens can be set by estimating the token distribution of the output. generation_seed is a parameter that is useful to seed outputs before generation and becomes important when you are running hyperparameter search to ensure reproducibility.
Also you do not want to generate tokens indefinitely till you hit the max_new_tokens, you want to stop when you hit a certain token or a certain sequence of tokens. You can use either eos_token_id or a stopping criteria.
# Get score & outputs using some generation parameters
tokenizer.pad_token = "<|end_of_text|>"
gen_params = {
'max_new_tokens' : 70,
'generation_seed' : 42,
'eos_token_id' : terminators,
}
score, outputs = tuner_ob.get_score(gen_params)
print(f"Score - {score}")
Hyperparameter SearchPermalink
Once you have instantiated the Tuner object, it exposes a tuner_ob.estimator which is a scikit-learn compatible BaseEstimator object. This can be used with scikit-learn methods. We will use it with GridSearchCV to run a hyperparameter search over the generation parameters.
First we define a hyperparameter space and a GridSearchCV/RandomSearchCV object and then fit it.
# Define your hyperparameter space here for the search
hyp_space = {
'max_new_tokens' : [70],
'generation_seed' : [42],
'do_sample' : [True],
'eos_token_id' : [terminators],
'temperature': [0.1, 0.2],
'top_k': [50, 60, 70],
'no_repeat_ngram_size': [0],
}
# Pass in estimator & scorer as you do with the scikit-learn API
clf = GridSearchCV(
estimator = tuner_ob.estimator,
param_grid=hyp_space,
scoring = tuner_ob.scorer,
cv = 2,
n_jobs = None, # we will run this sequentially
verbose=3,
)
The fit will take time depending on the number of fits that are expected to happen and the inference time per fit.
# fit on the dataset
clf.fit(X=tuner_ob.dataset["_X"], y=tuner_ob.dataset['_y'])
Once the model is fit you can view the best generation parameters from the search
# print out the best parameters
print(clf.best_params_)
Evaluation After TuningPermalink
Once you have the best parameters you can evaluate it on the full dataset using the tuner_ob.get_score method
scores, outputs = tuner_ob.get_score(clf.best_params_)
print(f"Scores - {scores}")
Additional UtilitiesPermalink
-
Logging Utilities - You can set the logging level of the library using this module
from llmsearch.utils.logging_utils import set_verbosity_info, set_verbosity_warning, set_verbosity_debug # set verbosity to debug, useful to debug model outputs set_verbosity_debug()The
DEBUGlevel is useful to see what is happening inside the library, for eg you want to see the text that is passed in to the model and the output that you get, here’s an example# Example Logs from the get score function - Calculate score on a different dataset scores, outputs = tuner_ob.get_score(gen_params, dataset = datasets.Dataset.from_dict(sample_dataset[:2])) -
Output
2024-06-05 18:19:26.099 - llmsearch.utils.mem_utils:154 - INFO - Starting inference with generation parameters - {'max_new_tokens': 70, 'generation_seed': 42, 'eos_token_id': [128001, 128009]} 2024-06-05 18:19:26.101 - llmsearch.utils.mem_utils:158 - INFO - Performing inference with batch_size - 2 2024-06-05 18:19:26.103 - llmsearch.utils.model_utils:98 - INFO - Detected generation type - Greedy Decoding 2024-06-05 18:19:29.759 - llmsearch.utils.model_utils:149 - DEBUG - Input - '<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nSummarize the following text in less than 50 words: Lucy: omg did you see JK this morning?\r\nSue: I try to avoid it lol\r\nLucy: you should have seen it it was disgusting\r\nSue: I cant do it anymore i try to listen to the radio in the mornings.. jk makes you think the whole world is full of idiots lol\r\nLucy: you may be right I dont know how some of them can go on there in public for the world to see\r\nSue: I would die if I got a call to go on there lol\r\nSue: could you imagine ha ha \r\nLucy: I would piss myself If I saw you and Andy up there\r\nSue: over my dead body !<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n' 2024-06-05 18:19:29.763 - llmsearch.utils.model_utils:150 - DEBUG - Model Output - 'The conversation is about a TV show "JK" that Lucy and Sue dislike. They\'re making fun of the show\'s content and the people who appear on it, calling them "idiots." They\'re joking about how they wouldn\'t want to be on the show themselves.' 2024-06-05 18:19:29.766 - llmsearch.utils.model_utils:149 - DEBUG - Input - "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are a helpful AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nSummarize the following text in less than 50 words: Wendy: What's up?\r\nSimon: Nothing much. I'm painting my cupboards. \r\nAngela: Cool what colour?\r\nSimon: Green.\r\nBen: I'm just chilling in the garden. \r\nAngela: Nice weekend! I'm about to meet Chris.\r\nWendy: Say hello from me!\r\nAngela: Will do! And how is your weekend, Wendy?\r\nWendy: Very lazy... The week was hard at work, I really needed some rest. \r\nBen: We should all come and visit Simon in his new apartment!\r\nSimon: You are welcome, guys! Whenever you wish.\r\nBen: I should be in Bournemouth next week. \r\nSimon: I'm not going anywhere :-)\r\nBen: Cool, I'll call you next week.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n" 2024-06-05 18:19:29.767 - llmsearch.utils.model_utils:150 - DEBUG - Model Output - "A group of friends chat about their weekends. Simon is painting his cupboards green, Angela is meeting Chris, and Ben is relaxing in the garden. They discuss visiting Simon's new apartment and make plans to catch up soon." 2024-06-05 18:19:30.159 - llmsearch.utils.mem_utils:176 - DEBUG - Setting batch_size cache value - 2 for this particular configuration 2024-06-05 18:19:30.161 - llmsearch.utils.mem_utils:188 - INFO - Finished running inference, took 4.057762 secs -
Multi Token Stopping Criteria - There could be a use-case where you want to stop your generation at a specific token other than the
eos_tokenor you want to stop the generation when a certain sequences of tokens occurs in the input. You can use theMultiTokenStoppingCriteriaavailable in llmsearchfrom transformers import StoppingCriteriaList from llmsearch.scripts.stopping_criteria import MultiTokenStoppingCriteria # specify what sequence to stop the generation on multi_token_stop_criteria_ob = MultiTokenStoppingCriteria(sequence_ids=[32000]) stopping_criteria = StoppingCriteriaList([multi_token_stop_criteria_ob]) callbacks_after_inference = [multi_token_stop_criteria_ob.reset] tuner_ob = Tuner( ... callbacks_after_inference=callbacks_after_inference, ... )MultiTokenStoppingCriteriahas the ability to operate on batches of input. It maintains a state for each batch that goes through it which helps it know where to look and what sequences in the batch have finished. This state is cleared after each inference run using the callback.
Conclusion ☕️Permalink
In this blog you got to know how you can utilize llmsearch to run hyperparameter search on generation parameters using scikit-learn. Would love to hear what the community does with it. In case of any feedback do not hesitate to reach out. llmsearch has multiple improvements planned as part of the v1.0.0. Stay tuned!
![]()
![]()


Comments