
Understanding the F1 Score metric for evaluating Grammar Error Correction Systems
Grammar Error Correction (GEC) in NLP is the task of making erroneous/grammatically incorrect sentences correct by performing a certain set of operations on the corrupted sentence.
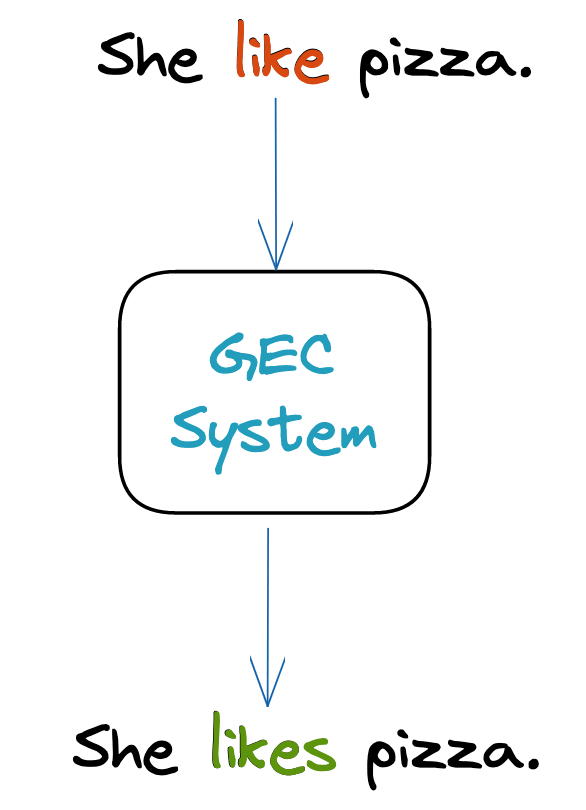
Classic GEC System
These operations can be:
- Replacement - You may replace a corrupted word with a corrected version of it.
- Insertion - You may insert a missing word in the sentence.
- Deletion - You may delete an unwanted word from the sentence.
F1 Score is a metric that is generally used to measure the performance of binary classification models. In this article, we will be understanding how you can use the F1 Score metric to evaluate GEC Systems as well. Some terminologies:
- Input/Corrupted Sentence - This is the corrupted sentence that we want to correct.
- Ground Truth - This is the corrected version of the Input Sentence.
- Hypothesis/Model Prediction - This is the sentence that your model predicted.
Now you want to measure your model performance w.r.t to the Ground Truth that you have. Before we jump to the metric, we need to understand what the M2 format is and how it relates to - Understanding F1 Metric for GEC.
The M2 FormatPermalink
This is a standard data format that is used in GEC tasks. Any annotation/model prediction of GEC can be expressed in this format, which has a corrupted sentence and the corrected version of it in terms of annotations/edits.
The below illustration explains what different parts of the format mean:

M2 Format
S - denotes Source Sentence
A - denotes Annotations/Edits, These can be Model predictions as well
A sentence can have more than one annotation -> More than one possible way to correct it.
There can be more than one edit in an annotation -> A correction with more than a single edit.
Few examples of the M2 Format:
S This are a sentence .
A 1 2|||R:VERB:SVA|||is|||-REQUIRED-|||NONE|||0
- Original sentence - This are a sentence.
- Annotations (1 Annotation)
- This is a sentence.
- The original sentence here is
This are a sentence. - The corrected version is
This is a sentence .whereare(at token offset -[1:2])is replaced byis.
S A dog over the wall .
A 2 2|||M:ADP|||jumped|||-REQUIRED-|||NONE|||0
A 1 2|||R:ADP|||cat|||-REQUIRED-|||NONE|||1
A 2 2|||M:ADP|||jumped|||-REQUIRED-|||NONE|||1
- Original Sentence - A dog over the wall
- Annotations (2 Annotations, 1st with 1 edit, 2nd with 2 edits)
- A dog jumped over the wall.
- A cat jumped over the wall.
S The boys played a game .
A 1 2 |||R:NOUN|||girls|||-REQUIRED-|||NONE|||0
A -1 -1|||noop|||-NONE-|||-REQUIRED-|||NONE|||1
- Original Sentence - The boys played a game.
- Annotations (2 Annotations, 1st with 1 edit, 2nd with noop edit)
- The
girlsplayed a game. - None (Here this means that the sentence is correct so Annotator/Model 1 annotated it as noop/having no annotation.)
- The
ERRANT(Error Annotation Toolkit) is one of the tools that you can use to get your output to the M2 format. While evaluating your model, you will have 2 M2 format annotations.
- Ground Truth M2 - an M2 Format Annotation between the Corrupted Sentence and the Ground Truth.
- Hypothesis M2 - an M2 Format Annotation between the Corrupted Sentence and the Hypothesis.
Now that you have understood the M2 format, Let’s take an example to see how we can calculate the metrics
- Corrupted Sentence - I am not play game .
- Ground Truth - I am not playing games .
- Hypothesis - I am not playing game .
Respective M2s(just the annotations):
-
Ground Truth M2
A 3 4 |||R:VERB|||playing|||-REQUIRED-|||NONE|||0 A 4 5 |||R:NOUN|||games|||-REQUIRED-|||NONE|||0 -
Hypothesis M2
A 3 4 |||R:VERB|||playing|||-REQUIRED-|||NONE|||0
Calculating the MetricsPermalink
Once we have the M2 format from the Ground Truth & Hypothesis M2, we can calculate the F1 metrics. In Grammar Error Correction, if you look at evaluation metrics, you will notice that often the F0.5 metric is mentioned. This is the F-Beta score with Beta=0.5 instead of F1(Beta=1). The lower Beta is the more you weigh Precision over Recall.
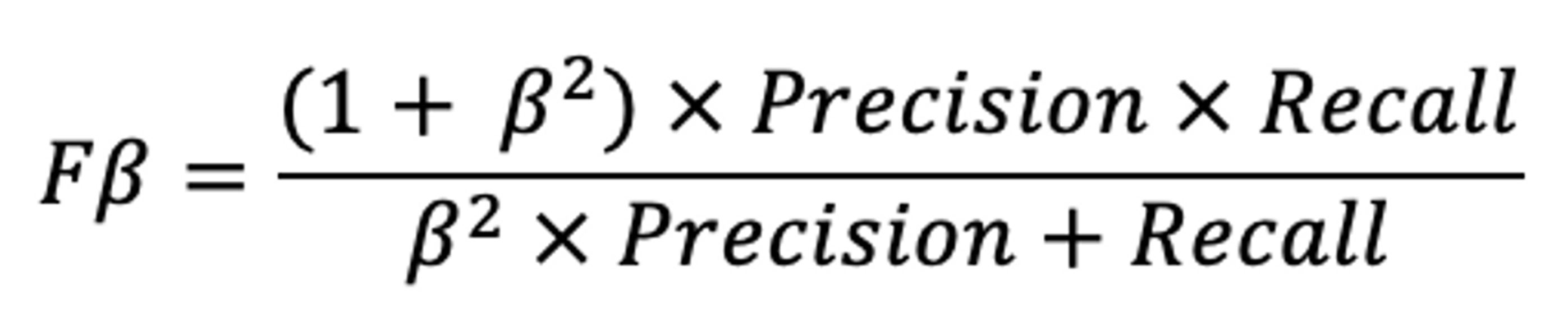
F-Beta Formula
In GEC you want to prevent introducing more false positives than identify every other error, that’s why we give more weight to precision than recall.
Here’s some pseudocode that explains how we calculate the F0.5 score from the M2s that we have.
# We think each of the edit in ground truth & hypothesis M2 to be the categories that we want to predict
# Initialize these to 0, There's no TN because we do not care for "non-errors"
tp, fp, fn = 0, 0, 0
# For each m2_edit in hypothesis_M2
for m2_edit in hypothesis_M2:
# Check if the hypothesis is a noop(nothing) edit, we don't include that in the metric calculation
if m2_edit = noop_edit:
continue
# Check if the same exact edit is present in ground_truth_M2, it's a True Positive if it exists
# Otherwise it's an FP (the edit that model suggested is incorrect)
if m2_edit in ground_truth_M2:
tp + =1
else:
fp += 1
# For each m2_edit in ground_truth_M2
for m2_edit in ground_truth_M2:
# Check if the ground_truth_M2 is a noop(nothing) edit, we don't include that in the metric calculation
if m2_edit = noop_edit:
continue
# For things that were supposed to be predicted but weren't, we put those in the False Negatives bucket
if m2_edit not in hypothesis_m2:
fn += 1
# Now you can calculate the metrics easily
precision, recall = tp / (tp + fp), tp / (tp + fn)
# Calculate F-0.5
f1_score = float((1 + (beta**2)) * precision * recall) / (((beta**2) * precision) + recall) if precision + recall else 0.0
In this article ☕️Permalink
- You understood what the M2 format is and how it is used in GEC
- Got to know how the F1 metric is applied to problems like GEC and not just vanilla classification problems.

Comments