
Ordering of set() when dealing with strings in python
While working on a baseline ML model for a side-project, I found that across different runs 🧪 of my experiments, the results that my model was generating were not exactly reproducible i.e. I was not getting the same performance metrics for the same model configuration, despite having all the knobs in place.
After debugging for quite some time, I found that this snippet was the root of my problems :
# create list of unique tokens using set
unique_tokens.extend(list(set(itertools.chain(*train_df.tokens.to_list()))))
config.VOCAB_SIZE = len(unique_tokens)
# create tokenizer mapping
token2id = {token : idx for idx, token in enumerate(unique_tokens)}
id2token = dict(enumerate(unique_tokens))
I was constructing the tokenizer mapping using the set() operation, this caused the same model i/o to be encoded & decoded differently each time.
And we’ll see why.
How set() worksPermalink
First, we need to understand how set() is implemented in python. Internally a set() data structure is implemented using a hash table. A hash table by definition has a hash function, which takes in the input and maps the data to a unique bucket using the hash value, this is how it can do membership checking in O(1).
When you call a set() on a list object, it returns unique values for the input that you provided. Internally to distinguish this “uniqueness” it uses the hash function we discussed above.
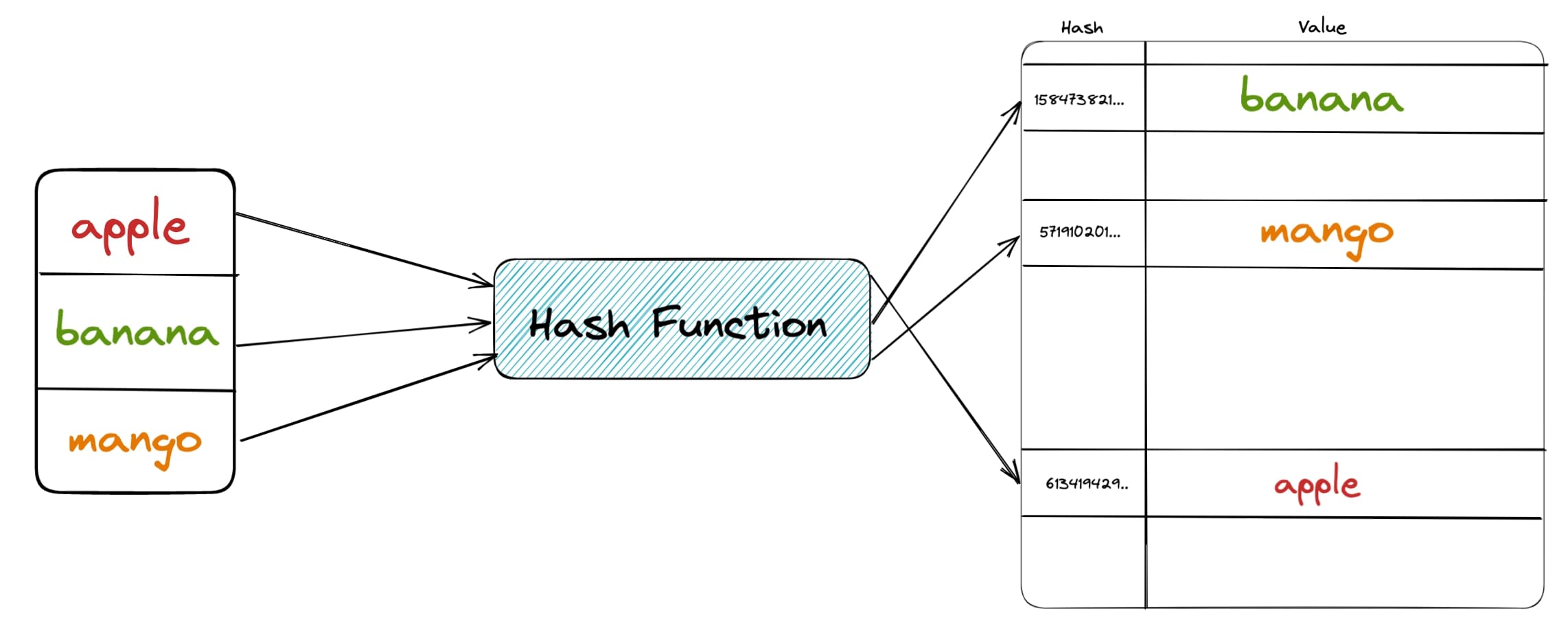
Hash Table
Converting a list into a set is easy, since for two similar values, both of them will map to the same exact hash bucket. However, this hash function is not always deterministic, particularly when dealing with string objects across two different python invocations. Let’s look at a few examples
"""snippet1.py"""
# Snippet to get hash values
a = "1"
b = "abcde"
c = 1234
d = 6.4512
hv1 = hash(a)
hv2 = hash(b)
hv3 = hash(c)
hv4 = hash(d)
print(f"Hash value of {a} - {hv1}")
print(f"Hash value of {b} - {hv2}")
print(f"Hash value of {c} - {hv3}")
print(f"Hash value of {d} - {hv4}")
This is what I got from two different invocations of the script
$ python snippet1.py
Hash value of 1 - 1981388520896787279
Hash value of abcde - 4943320557970621589
Hash value of 1234 - 1234
Hash value of 6.4512 - 1040396365757218822
$ python snippet1.py
Hash value of 1 - -9001918643517506909
Hash value of abcde - -757009308147773598
Hash value of 1234 - 1234
Hash value of 6.4512 - 1040396365757218822
You can notice how I got different outputs across two different invocations of the script for the variables that are string. While the hash values for the numbers remained constant.
This is because of how internally hash function is implemented. For values of str and byte objects, the input to the hash function is salted with a random value to protect against certain denial of service attacks(source). For the same python invocation, the value remains the same, as this “salting” only happens at the first time you call the python executable.
But how do these hash values link to the ordering of the sets 🤔
In the set() data structure, after hashing is done for an object, python takes the last N bits of the hash value and uses them as indices to place the object in the memory. And when these values are retrieved from the memory, they are yielded in the order that they exist in the memory not the way they were put in.
And what happens to the order when you have different hash values across different python invocations?
Here’s an example to make the concept concrete:
"""snippet2.py"""
l1 = [9,1,1,2,3,4,5,1,1,2]
l2 = ["def",2,3,4,"abc", "abc", "deg", "xyz"]
s1 = set(l1)
s2 = set(l2)
print(f"Set 1 - {set(s1)}")
print(f"Set 2 - {set(s2)}")
Output from two different invocations
$ python snippet2.py
Set 1 - {1, 2, 3, 4, 5, 9}
Set 2 - {'xyz', 2, 3, 4, 'deg', 'def', 'abc'}
$ python snippet2.py
Set 1 - {1, 2, 3, 4, 5, 9}
Set 2 - {2, 3, 4, 'def', 'abc', 'xyz', 'deg'}
You’ll notice how for set 2 the ordering is different.
For the two separate runs, since the strings have different hash values, they have been mapped to different locations in the memory which then affected the ordering when it was yeilded from the memory. 💡
Can this be fixed?Permalink
By virtue, python sets are unordered, so it is better if alternatives are explored, As of Python 3.7+, dicts are ordered, so a hack like this would work:
sample_list = ["def",2,3,4,"abc", "abc", "deg", "xyz"]
sample_set = list(dict.fromkeys(sample_list))
This is how I modified my code
# create list of unique tokens using dict
unique_tokens.extend(
list(dict.fromkeys(itertools.chain(*_df.tokens.to_list())))
)
config.VOCAB_SIZE = len(unique_tokens)
# create tokenizer mapping
token2id = {token: idx for idx, token in enumerate(unique_tokens)}
id2token = dict(enumerate(unique_tokens))
If you still need to use set and preserve ordering across different runs(not recommended), the env variable PYTHONHASHSEED can be set to ‘0’ to disable randomization.
import os
import sys
hash_seed = os.getenv('PYTHONHASHSEED')
if not hash_seed:
os.environ['PYTHONHASHSEED'] = '0'
# Spaw a new/child process and run the same file
os.execv(sys.executable, [sys.executable] + sys.argv)
# Your code below
l1 = [9,1,1,2,3,4,5,1,1,2]
l2 = ["def",2,3,4,"abc", "abc", "deg", "xyz"]
s1 = set(l1)
s2 = set(l2)
print(f"Set 1 - {set(s1)}")
print(f"Set 2 - {set(s2)}")
This snippet will turn off the randomization/salting that happens. This is done by setting a env variable and then spawning a new/child process which runs the same python file again. So that the new python invocation will use the value of the set env variable.
Running this snippet will give you the same ordering each time. Try it out : )
In this article ☕️Permalink
- You understood how & why sets are unordered
- How you can make them ordered
- Alternatives to preserve ordering and get unique values
Find the snippets from this blog over here : )


Comments